С помощью которого моделируются многие реальные процессы. И самый такой распространённый пример – это график движения общественного транспорта. Предположим, что некий автобус (троллейбус / трамвай) ходит с интервалом в 10 минут, и вы в случайный момент времени подошли к остановке. Какова вероятность того, что автобус подойдёт в течение 1 минуты? Очевидно, 1/10-я. А вероятность того, что придётся ждать 4-5 минут? Тоже . А вероятность того, что автобус придётся ждать более 9 минут? Одна десятая!
Рассмотрим некоторый конечный
промежуток, пусть для определённости это будет отрезок . Если случайная величина
обладает постоянной
плотностью распределения вероятностей
на данном отрезке и нулевой плотностью вне него, то говорят, что она распределена равномерно
. При этом функция плотности будет строго определённой:
И в самом деле, если длина отрезка (см. чертёж)
составляет , то значение неизбежно равно – дабы получилась единичная площадь прямоугольника, и было соблюдено известное свойство
:
Проверим его формально:
, ч.т.п. С вероятностной точки зрения это означает, что случайная величина достоверно
примет одно из значений отрезка …, эх, становлюсь потихоньку занудным старикашкой =)
Суть равномерности состоит в том, что какой бы внутренний промежуток фиксированной длины мы ни рассмотрели (вспоминаем «автобусные» минуты) – вероятность того, что случайная величина примет значение из этого промежутка будет одной и той же. На чертеже я заштриховал троечку таких вероятностей – ещё раз заостряю внимание, что они определяются площадями , а не значениями функции !
Рассмотрим типовое задание:
Пример 1
Непрерывная случайная величина задана своей плотностью распределения:![]()
Найти константу , вычислить и составить функцию распределения. Построить графики . Найти
Иными словами, всё, о чём только можно было мечтать:)
Решение
: так как на интервале (конечном промежутке)
![]() , то случайная величина имеет равномерное распределение, и значение «цэ» можно отыскать по прямой формуле
, то случайная величина имеет равномерное распределение, и значение «цэ» можно отыскать по прямой формуле ![]() . Но лучше общим способом – с помощью свойства:
. Но лучше общим способом – с помощью свойства:
…почему лучше? Чтобы не было лишних вопросов;)
Таким образом, функция плотности:
Выполним чертёж. Значения невозможны
, и поэтому жирные точки ставятся внизу:
В качестве экспресс-проверки вычислим площадь прямоугольника:![]() , ч.т.п.
, ч.т.п.
Найдём математическое ожидание , и, наверное, вы уже догадываетесь, чему оно равно. Вспоминаем «10-минутный» автобус: если случайным образом подходить к остановке много-много дней упаси, то в среднем его придётся ждать 5 минут.
Да, именно так – матожидание должно находиться ровно посерединке «событийного» промежутка:
, как и предполагалось.
Дисперсию вычислим по формуле
![]() . И вот тут нужен глаз да глаз при вычислении интеграла:
. И вот тут нужен глаз да глаз при вычислении интеграла:
Таким образом, дисперсия
: ![]()
Составим функцию распределения
![]() . Здесь ничего нового:
. Здесь ничего нового:
1) если , то и ![]() ;
;
2) если , то и:
3) и, наконец, при ![]() , поэтому:
, поэтому:
В результате:
Выполним чертёж:
На «живом» промежутке функция распределения растёт
линейно
, и это ещё один признак, что перед нами равномерно распределённая случайная величина. Ну, ещё бы, ведь производная
линейной функции
– есть константа.
Требуемую вероятность можно вычислить двумя способами, с помощью найденной функции распределения:
либо с помощью определённого интеграла от плотности:
Кому как нравится.
И здесь ещё можно записать ответ
: , , графики построены по ходу решения.
, графики построены по ходу решения.
…«можно», потому что за его отсутствие обычно не карают. Обычно;)
Для вычисления и равномерной случайной величины существуют специальные формулы, которые я предлагаю вам вывести самостоятельно:
Пример 2
Непрерывная случайная величина задана плотностью  .
.
Вычислить математическое ожидание и дисперсию. Результаты максимально упростить (формулы сокращённого умножения в помощь) .
Полученные формулы удобно использовать для проверки, в частности, проверьте только что прорешанную задачу, подставив в них конкретные значения «а» и «б». Краткое решение внизу страницы.
И в заключение урока мы разберём парочку «текстовых» задач:
Пример 3
Цена деления шкалы измерительного прибора равна 0,2. Показания прибора округляются до ближайшего целого деления. Считая, что погрешности округлений распределены равномерно, найти вероятность того, что при очередном измерении она не превзойдёт 0,04.
Для лучшего понимания решения представим, что это какой-нибудь механический прибор со стрелкой, например, весы с ценой деления 0,2 кг, и нам предстоит взвесить кота в мешке. Но не в целях выяснить его упитанность – сейчас будет важно, ГДЕ между двумя соседними делениями остановится стрелка.
Рассмотрим случайную величину – расстояние стрелки от ближайшего левого деления. Или от ближайшего правого, это не принципиально.
Составим функцию плотности распределения вероятностей:
1) Так как расстояние не может быть отрицательным, то на интервале . Логично.
2) Из условия следует, что стрелка весов с равной вероятностью
может остановиться в любом месте между делениями*
, включая сами деления, и поэтому на промежутке :![]()
* Это существенное условие. Так, например, при взвешивании кусков ваты или килограммовых пачек соли равномерность будет соблюдаться на куда более узких промежутках.
3) И поскольку расстояние от БЛИЖАЙШЕГО левого деления не может быть больше, чем 0,2, то при тоже равна нулю.
Таким образом:
Следует отметить, что о функции плотности нас никто не спрашивал, и её полное построения я привёл исключительно в познавательных цепях. При чистовом оформлении задачи достаточно записать только 2-й пункт.
Теперь ответим на вопрос задачи. Когда погрешность округления до ближайшего деления не превзойдёт 0,04? Это произойдёт тогда, когда стрелка остановится не далее чем на 0,04 от левого деления справа
или
не далее чем на 0,04 от правого деления слева
. На чертеже я заштриховал соответствующие площади:
Осталось найти эти площади с помощью интегралов
. В принципе, их можно вычислить и «по-школьному» (как площади прямоугольников), но простота не всегда находит понимание;)
По теореме сложения вероятностей несовместных событий
:
– вероятность того, что ошибка округления не превзойдёт 0,04 (40 грамм для нашего примера)
Легко понять, что максимально возможная погрешность округления составляет 0,1 (100 грамм) и поэтому вероятность того, что ошибка округления не превзойдёт 0,1 равна единице. И из этого, кстати, следует другой, более лёгкий способ решения, в котором нужно рассмотреть случайную величину – погрешность округления до ближайшего деления . Но первый способ мне пришёл в голову первым:)
Ответ : 0,4
И ещё один момент по задаче . В условии речь может идти о погрешностях не округлений , а о случайных погрешностях самих измерений , которые, как правило (но не всегда) , распределены по нормальному закону . Таким образом, всего лишь одно слово может в корне изменить решение! Будьте начеку и вникайте в смысл задач!
И коль скоро всё идёт по кругу, то ноги нас приносят на ту же остановку:
Пример 4
Автобусы некоторого маршрута идут строго по расписанию и интервалом 7 минут. Составить функцию плотности случайной величины – времени ожидании очередного автобуса пассажиром, который наудачу подошёл к остановке. Найти вероятность того, что он будет ждать автобус не более трёх минут. Найти функцию распределения и пояснить её содержательный смысл.
В качестве примера непрерывной случайной величины рассмотрим случайную величину X, равномерно распределенную на интервале (a; b). Говорят, что случайная величина X равномерно распределена на промежутке (a; b), если ее плотность распределения непостоянна на этом промежутке:
Из условия нормировки определим значение константы c . Площадь под кривой плотности распределения должна быть равна единице, но в нашем случае - это площадь прямоугольника с основанием (b - α) и высотой c (рис. 1).

Рис. 1 Плотность равномерного распределения
Отсюда находим значение постоянной c:
![]()
Итак, плотность равномерно распределенной случайной величины равна

Найдем теперь функцию распределения по формуле:
1) для ![]()
2) для
3) для 0+1+0=1.
Таким образом,
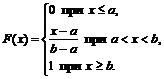
Функция распределения непрерывна и не убывает (рис. 2).

Рис. 2 Функция распределения равномерно распределенной случайной величины
Найдем математическое ожидание равномерно распределенной случайной величины по формуле:
Дисперсия равномерного распределения рассчитывается по формуле и равна
Пример №1
. Цена деления шкалы измерительного прибора равна 0.2 . Показания прибора округляют до ближайшего целого деления. Найти вероятность того, что при отсчете будет сделана ошибка: а) меньшая 0.04 ; б) большая 0.02
Решение. Ошибка округления есть случайная величина, равномерно распределенная на промежутке между соседними целыми делениями. Рассмотрим в качестве такого деления интервал (0; 0,2) (рис. а). Округление может проводиться как в сторону левой границы - 0, так и в сторону правой - 0,2, значит, ошибка, менее либо равная 0,04, может быть сделана два раза, что необходимо учесть при подсчете вероятности:


P = 0,2 + 0,2 = 0,4
Для второго случая величина ошибки может превышать 0,02 также с обеих границ деления, то есть она может быть либо больше 0,02, либо меньше 0,18.

Тогда вероятность появления такой ошибки:
Пример №2 . Предполагалось, что о стабильности экономической обстановки в стране (отсутствии войн, стихийных бедствий и т. д.) за последние 50 лет можно судить по характеру распределения населения по возрасту: при спокойной обстановке оно должно быть равномерным . В результате проведенного исследования, для одной из стран были получены следующие данные.
Имеются ли основания полагать, что в стране была нестабильная обстановка?Решение проводим с помощью калькулятора Проверка гипотез . Таблица для расчета показателей.
| Группы | Середина интервала, x i | Кол-во, f i | x i * f i | Накопленная частота, S | |x - x ср |*f | (x - x ср) 2 *f | Частота, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Средняя взвешенная
Показатели вариации .
Абсолютные показатели вариации .
Размах вариации - разность между максимальным и минимальным значениями признака первичного ряда.
R = X max - X min
R = 70 - 0 = 70
Дисперсия - характеризует меру разброса около ее среднего значения (мера рассеивания, т.е. отклонения от среднего).

Среднее квадратическое отклонение .
Каждое значение ряда отличается от среднего значения 43 не более, чем на 23.92
Проверка гипотез о виде распределения .
4. Проверка гипотезы о равномерном распределении генеральной совокупности.
Для того чтобы проверить гипотезу о равномерном распределении X,т.е. по закону: f(x) = 1/(b-a) в интервале (a,b)
надо:
1. Оценить параметры a и b - концы интервала, в котором наблюдались возможные значения X, по формулам (через знак * обозначены оценки параметров):
2. Найти плотность вероятности предполагаемого распределения f(x) = 1/(b * - a *)
3. Найти теоретические частоты:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Сравнить эмпирические и теоретические частоты с помощью критерия Пирсона, приняв число степеней свободы k = s-3, где s - число первоначальных интервалов выборки; если же было произведено объединение малочисленных частот, следовательно, и самих интервалов, то s - число интервалов, оставшихся после объединения.
Решение:
1. Найдем оценки параметров a * и b * равномерного распределения по формулам:
2. Найдем плотность предполагаемого равномерного распределения:
f(x) = 1/(b * - a *) = 1/(84.42 - 1.58) = 0.0121
3. Найдем теоретические частоты:
n 1 = n*f(x)(x 1 - a *) = 1 * 0.0121(10-1.58) = 0.1
n 8 = n*f(x)(b * - x 7) = 1 * 0.0121(84.42-70) = 0.17
Остальные n s будут равны:
n s = n*f(x)(x i - x i-1)
| i | n i | n * i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Итого | 1 | 0.0532 |
Поэтому критическая область для этой статистики всегда правосторонняя: , если на этом отрезке плотность распределения постоянна, а вне его - равна 0.
Кривая равномерного распределения показана на рис. 3.13.

Рис. 3.13.
Значения/(х) в крайних точках а и Ь участка (а, Ь) не указываются, так как вероятность попадания в любую из этих точек для непрерывной случайной величины X равна 0.
Математическое ожидание случайной величины X, имеющей равномерное распределение на участке [а, й], /« = (а + Ь)/2. Дисперсия вычисляется по формуле D =(Ь- а)2/12, отсюда ст = (Ь - а)/3,464.
Моделирование случайных величин. Для моделирования случайной величины необходимо знать ее закон распределения. Наиболее общим способом получения последовательности случайных чисел, распределенных по произвольному закону, является способ, в основе которого лежит их формирование из исходной последовательности случайных чисел, распределенных в интервале (0; 1) по равномерному закону.
Равномерно распределенные в интервале (0; 1) последовательности случайных чисел можно получить тремя способами:
- по специально подготовленным таблицам случайных чисел;
- с применением физических генераторов случайных чисел (например, бросанием монеты);
- алгоритмическим методом.
Для таких чисел величина математического ожидания должна быть равна 0,5, а дисперсия - 1/12. Если необходимо, чтобы случайное число X находилось в интервале (а ; Ь), отличном от (0; 1), нужно воспользоваться формулой Х=а + (Ь- а)г, где г - случайное число из интервала (0; 1).
В связи с тем, что практически все модели реализуются на компьютере, почти всегда для получения случайных чисел используют встроенный в ЭВМ алгоритмический генератор (ГСЧ), хотя не составляет проблем использовать и таблицы, предварительно переведенные в электронный вид. Следует учитывать, что алгоритмическим методом мы всегда получаем псевдослучайные числа, так как каждое последующее сгенерированное число зависит от предыдущего.
На практике всегда необходимо получить случайные числа, распределенные по заданному закону распределения. Для этого используются самые разнообразные методы. Если известно аналитическое выражение для закона распределения F, то можно использовать метод обратных функций.
Достаточно разыграть случайное число, равномерно распределенное в интервале от 0 до 1. Поскольку функция F тоже изменяется в данном интервале, то случайное число X можно определить взятием обратной функции по графику или аналитически: х = F "(г). Здесь г - число, генерируемое ГСЧ в интервале от 0 до 1; x t - сгенерированная в итоге случайная величина. Графически суть метода изображена на рис. 3.14.

Рис. 3.14. Иллюстрация метода обратной функции для генерации случайных событий X , значения которых распределены непрерывно. На рисунке показаны графики плотности вероятности и интегральной плотности вероятности от х
Рассмотрим в качестве примера экспоненциальный закон распределения. Функция распределения этого закона имеет вид F(x) = 1 -ехр(-Ъг). Так как г и F в данном методе предполагаются аналогичными и расположены в одном интервале, то, заменяя F на случайное число г, имеем г = 1 - ехр(-Ъг). Выражая искомую величину х из этого выражения (т. е. обращая функцию ехр()), получаем х = -/Х? 1п(1 -г). Так как в статистическом смысле (1 - г) и г - это одно и то же, то х = -УХ 1п(г).
Алгоритмы моделирования некоторых распространенных законов распределения непрерывных случайных величин приведены в табл. 3.10.
Например, необходимо смоделировать время погрузки, которое распределено по нормальному закону. Известно, что средняя продолжительность погрузки составляет 35 мин, а среднеквадратичное отклонение реального времени от средней величины составляет 10 мин. То есть по условиям задачи т х = 35, с х = 10. Тогда значение случайной величины будет рассчитываться по формуле R = ?г, где г. - случайные числа из ГСЧ в диапазоне , п = 12. Число 12 выбрано как достаточно большое на основании центральной предельной теоремы теории вероятностей (теоремы Ляпунова): «Для большого числа N случайных величин X с любым законом распределения их сумма есть случайное число с нормальным законом распределения». Тогда случайное значение X = о (7? - л/2) + т х = 10(7? -3) + 35.
Таблица 3.10
Алгоритмы моделирования случайных величин
Моделирование случайного события. Случайное событие подразумевает, что у некоторого события есть несколько исходов и который из исходов произойдет в очередной раз, определяется только его вероятностью. То есть исход выбирается случайно с учетом его вероятности. Например, допустим, что нам известна вероятность выпуска бракованных изделий Р = 0,1. Смоделировать выпадение этого события можно, разыграв равномерно распределенное случайное число из диапазона от 0 до 1 и установив, в какой из двух интервалов (от 0 до 0,1 или от 0,1 до 1) оно попало (рис. 3.15). Если число попадает в диапазон (0; 0,1), то выпущен брак, т. е. событие произошло, иначе - событие не произошло (выпущено кондиционное изделие). При значительном числе экспериментов частота попадания чисел в интервал от 0 до 0,1 будет приближаться к вероятности Р= 0,1, а частота попадания чисел в интервал от 0,1 до 1 будет приближаться к Р. = 0,9.

Рис. 3.15.
События называются несовместными , если вероятность появления этих событий одновременно равна 0. Отсюда следует, что суммарная вероятность группы несовместных событий равна 1. Обозначим через a r я, a n события, а через Р ]9 Р 2 , ..., Р п - вероятности появления отдельных событий. Так как события несовместны, то сумма вероятностей их выпадения равна 1: Р х + Р 2 + ... + P n = 1. Снова используем для имитации выпадения одного из событий генератор случайных чисел, значение которых также всегда находится в диапазоне от 0 до 1. Отложим на единичном интервале отрезки P r P v ..., Р п. Понятно, что в сумме отрезки составят точно единичный интервал. Точка, соответствующая выпавшему числу из генератора случайных чисел на этом интервале, укажет на один из отрезков. Соответственно в большие отрезки случайные числа будут попадать чаще (вероятность появления этих событий больше!), в меньшие отрезки - реже (рис. 3.16).
При необходимости моделирования совместных событий их необходимо привести к несовместным. Например, чтобы смоделировать появление событий, для которых заданы вероятности Р(а {) = 0,7; Р(а 2) = 0,5 и Р(а ]9 а 2) = 0,4, определим все возможные несовместные исходы появления событий а г а 2 и их одновременного появления:
- 1. Одновременное появление двух событий Р(Ь {) = Р(а Л , а 2) = 0,4.
- 2. Появление события а ] Р(Ь 2) = Р(а у) - Р(а { , а 2) = 0,7 - 0,4 = 0,3.
- 3. Появление события а 2 Р(Ь 3) = Р(а 2) - Р(а г а 2) = 0,5 - 0,4 = 0,1.
- 4. Непоявление ни одного события P(b 4) = 1 - (Р(Ь) + Р(Ь 2) + + Р(Ь 3)) =0,2.
Теперь вероятности появления несовместных событий b необходимо представить на числовой оси в виде отрезков. Получая с помощью ГСЧ числа, определяем их принадлежность тому или иному интервалу и получаем реализацию совместных событий а.

Рис. 3.16.
Часто на практике встречаются системы случайных величин , т. е. такие две (и более) различные случайные величины X , У (и другие), которые зависят друг от друга. Например, если произошло событие X и приняло какое-то случайное значение, то событие У происходит хотя и случайно, но с учетом того, что X уже приняло какое-то значение.
Например, если в качестве X выпало большое число, то в качестве У должно выпасть тоже достаточно большое число (если корреляция положительна, и наоборот, если отрицательна). На транспорте такие зависимости встречаются достаточно часто. Большая длительность задержек более вероятна на маршрутах существенной протяженности и т. д.
Если случайные величины зависимы, то
f(x)=f(x l)f(x 2 x l)f(x 3 x 2 ,x l)- ... -/(xjx, r X„ , ...,x 2 ,x t), где x. | x._ v x { - случайные зависимые величины: выпадение х. при условии, что выпалих._ {9 х._ { , ...,*,)- плотность условной
вероятности появления х.> если выпали х._ {9 ..., х { ; f (х) - вероятность выпадения вектора х случайных зависимых величин.
Коэффициент корреляции q показывает, насколько тесно связаны события Хи У. Если коэффициент корреляции равен единице, то зависимость событий Хи У взаимно однозначная: одному значению X соответствует одно значение У (рис. 3.17, а) . При q , близких к единице, возникает картина, показанная на рис. 3.17, б, т. е. одному значению X могут соответствовать уже несколько значений У (точнее, одно из нескольких значений У, определяемое случайным образом); т. е. в этом событии X и Y менее коррелированы, менее зависимы друг от друга.

Рис. 3.17. Вид зависимости двух случайных величин при положительном коэффициенте корреляции: a - при q = 1; б - при 0 q при q, близком к О
И, наконец, когда коэффициент корреляции стремится к нулю, возникает ситуация, при которой любому значению X может соответствовать любое значение У, т. е. события X и Y не зависят или почти не зависят друг от друга, не коррелируют друг с другом (рис. 3.17, в).
Для примера возьмем нормальное распределение, как самое распространенное. Математическое ожидание указывает на самые вероятные события, здесь число событий больше и график событий гуще. Положительная корреляция указывает, что большие случайные величины X вызывают к генерации большие Y. Нулевая и близкая к нулю корреляция показывает, что величина случайной величины X никак не связана с определенным значением случайной величины Y. Легко понять сказанное, если представить себе сначала распределения f(X) и/(У) отдельно, а потом связать их в систему, как это представлено на рис. 3.18.
В рассматриваемом примере Хи У распределены по нормальному закону с соответствующими значениями т х, а и т у, а,. Задан коэффициент корреляции двух случайных событий q , т. е. случайные величины X и У зависимы друг от друга, У не совсем случайно.
Тогда возможный алгоритм реализации модели будет следующим:
1. Разыгрывается шесть случайных равномерно распределенных на интервале чисел: б р b: , б я, б 4 , Ь 5 , б 6 ; находится их сумма S :
S = ЪЬ. Находится нормально распределенное случайное число л: по следующей формуле: х = а (5 - 6) + т х.
- 2. По формуле т!х = т у + qoJo x {x -т х) находится математическое ожидание т у1х (знак у/х означает, что у будет принимать случайные значения с учетом условия, что * уже принял какие-то определенные значения).
- 3. По формуле = а д/l-Ц 2 находится среднеквадратическое отклонение а..
4. Разыгрывается 12 случайных равномерно распределенных на интервале чисел г; находится их сумма к: к = Zr. Находится нормально распределенное случайное число у по следующей формуле: y = °Jk-6) + m r/x .

Рис. 3.18.
Моделирование потока событии. Когда событий много и они следуют друг за другом, то они образуют поток. Заметим, что события при этом должны быть однородными, т. е. похожими чем-то друг на друга. Например, появление водителей на АЗС, желающих заправить свой автомобиль. То есть однородные события образуют некий ряд. При этом считается, что статистическая характеристика этого 146
явления (интенсивность потока событий) задана. Интенсивность потока событий указывает, сколько в среднем происходит таких событий за единицу времени. Но когда именно произойдет каждое конкретное событие, надо определить методами моделирования. Важно, что, когда мы сгенерируем, например, за 200 ч 1000 событий, их количество будет равно примерно величине средней интенсивности появления событий 1000/200 = 5 событий в час. Это является статистической величиной, характеризующей этот поток в целом.
Интенсивность потока в некотором смысле является математическим ожиданием количества событий в единицу времени. Но реально может так оказаться, что в один час появится 4 события, в другой - 6, хотя в среднем получается 5 событий в час, поэтому одной величины для характеристики потока недостаточно. Второй величиной, характеризующей, насколько велик разброс событий относительно математического ожидания, является, как и ранее, дисперсия. Именно эта величина определяет случайность появления события, слабую предсказуемость момента его появления.
Случайные потоки бывают:
- ординарные - вероятность одновременного появления двух и более событий равна нулю;
- стационарные - частота появления событий X постоянна;
- без последействия - вероятность появления случайного события не зависит от момента совершения предыдущих событий.
При моделировании СМО в подавляющем числе случаев рассматривается пуассоновский (простейший) поток - ординарный поток без последействия, в котором вероятность поступления в промежуток времени t ровно т требований задается формулой Пуассона:
Пуассоновский поток может быть стационарным, если А.(/) = const(/), или нестационарным в противном случае.
В пуассоновском потоке вероятность того, что ни одно событие не наступит,
На рис. 3.19 приведена зависимость Р от времени. Очевидно, что чем больше время наблюдения, тем вероятность, что ни одно событие не произойдет, меньше. Кроме того, чем более значение X, тем круче идет график, т. е. быстрее убывает вероятность. Это соответствует тому, что если интенсивность появления событий велика, то вероятность того, что событие не произойдет, быстро уменьшается со временем наблюдения.

Рис. 3.19.
Вероятность появления хотя бы одного события Р = 1 - схр(-Ад), так как Р + Р = . Очевидно, что вероятность появления хотя бы одного события стремится со временем к единице, т. е. при соответствующем длительном наблюдении событие обязательно рано или поздно произойдет. По смыслу Р равно г, поэтому, выражая / из формулы определения Р, окончательно для определения интервалов между двумя случайными событиями имеем
![]()
где г- равномерно распределенное от 0 до 1 случайное число, которое получают с помощью ГСЧ; t - интервал между случайными событиями (случайная величина).
В качестве примера рассмотрим поток автомобилей, прибывающих на терминал. Автомобили приходят случайным образом - в среднем 8 за сутки (интенсивность потока X = 8/24 авт./ч). Необходимо смо- 148
делировать этот процесс в течение Т = 100 ч. Средний интервал времени между автомобилями / = 1/Л. = 24/8 = 3 ч.
На рис. 3.20 показан результат моделирования - моменты времени, когда автомобили приходили на терминал. Как видно, всего за период Т = 100 терминал обработал N=33 автомобиля. Если запустить моделирование снова, то N может оказаться равным, например, 34, 35 или 32. Но в среднем за К прогонов алгоритма N будет равно 33,333.
Рис. 3.20.
Если известно, что поток не является ординарным, то необходимо моделировать кроме момента возникновения события еще и число событий, которое могло появиться в этот момент. Например, автомобили на терминал прибывают в случайные моменты времени (ординарный поток автомобилей). Но при этом в автомобилях может быть разное (случайное) количество груза. В этом случае о потоке груза говорят как о потоке неординарных событий.
Рассмотрим задачу. Необходимо определить время простоя по- 1рузочного оборудования на терминале, если автомобилями на терминал доставляются контейнеры АУК-1,25. Поток автомобилей подчиняется закону Пуассона, средний интервал между автомобилями равен 0,5 чД = 1/0,5 = 2 авт./ч. Количество контейнеров в автомобиле варьируется по нормальному закону со средним значением т = 6 и а = 2. При этом минимально может быть 2, а максимально - 10 контейнеров. Время разгрузки одного контейнера составляет 4 мин и 6 мин необходимо на технологические операции. Алгоритм решения этой задачи, построенный по принципу последовательной проводки каждой заявки, приведен на рис. 3.21.
После ввода исходных данных запускается цикл моделирования до достижения заданного модельного времени. С помощью ГСЧ получаем случайное число, затем определяем интервал времени до прихода автомобиля. Отмечаем полученный интервал на оси времени и моделируем количество контейнеров в кузове прибывшего автомобиля.
Проверяем полученное число на допустимый интервал. Далее вычисляется время разгрузки и суммируется в счетчике общего времени работы погрузочного оборудования. Проверяется условие: если интервал прихода автомобиля больше времени разгрузки, то разность между ними суммируем в счетчике времени простоя оборудования.

Рис. 3.21.
Типичным примером для СМО может являться работа пункта погрузки с несколькими постами, как это показано на рис. 3.22.

Рис. 3.22.
Для наглядности процесса моделирования построим временную диаграмму работы СМО, отражая на каждой линейке (ось времени /) состояние отдельного элемента системы (рис. 3.23). Временных линеек проводится столько, сколько имеется различных объектов в СМО (потоков). В нашем примере их 7: поток заявок, поток ожидания на первом месте в очереди, поток ожидания на втором месте в очереди, поток обслуживания в первом канале, поток обслуживания во втором канале, поток обслуженных системой заявок, поток отказанных заявок. Для демонстрации процесса отказа в обслуживании условимся, что в очереди на погрузку могут находиться только два автомобиля. Если их больше, то они направляются на другой пункт погрузки.
Смоделированные случайные моменты поступления заявок на обслуживание автомобилей отображены на первой линейке. Берется первая заявка и, так как в этот момент каналы свободны, устанавливается на обслуживание в первый канал. Заявка 1 переносится на линейку первого канала. Время обслуживания в канале тоже случайное. Находим на диаграмме момент окончания обслуживания, откладывая сгенерированное время обслуживания от момента начала обслужива-
ния, и опускаем заявку на линейку «Обслуженные». Заявка прошла в СМО весь путь. Теперь можно согласно принципу последовательной проводки заявок так же смоделировать путь второй заявки.

Рис. 3.23.
Если в некоторый момент окажется, что оба канала заняты, то следует установить заявку в очередь. На рис. 3.23 это заявка 3. Заметим, что по условиям задачи в очереди, в отличие от каналов, заявки находятся не случайное время, а ожидают, когда освободится какой-то из каналов. После освобождения канала заявка поднимается на линейку соответствующего канала и там организуется ее обслуживание.
Если вес места в очереди в момент, когда придет очередная заявка, будут заняты, то заявку следует отправить на линейку «Отказанные». На рис. 3.23 это заявка 6.
Процедуру имитации обслуживания заявок продолжают некоторое время Т . Чем больше это время, тем точнее в дальнейшем будут результаты моделирования. Реально для простых систем выбирают Т , равное 50-100 ч и более, хотя иногда лучше мерить эту величину количеством рассмотренных заявок.
Анализ СМО проведем на уже рассмотренном примере.
Сначала нужно дождаться установившегося режима. Откидываем первые четыре заявки как нехарактерные, протекающие во время процесса установления работы системы («время разогрева модели»). Измеряем время наблюдения, допустим, что в нашем примере Г = 5 ч. Подсчитываем из диаграммы количество обслуженных заявок N o6c , время простоя и другие величины. В результате можем вычислить показатели, характеризующие качество работы СМО:
- 1. Вероятность обслуживания Р = N,/N= 5/7 = 0,714. Для расчета вероятности обслуживания заявки в системе достаточно разделить число заявок, которое удалось обслужить за время Т (см. линейку «Обслуженные»), Л/ о6с на число заявок N, которые поступили за эго же время.
- 2. Пропускная способность системы А = NJT h = 7/5 = 1,4 авт./ч. Для расчета пропускной способности системы достаточно разделить число обслуженных заявок N o6c на время Т, за которое произошло это обслуживание.
- 3. Вероятность отказа Р = N /N=3/7 = 0,43. Для расчета всро- ятности отказа заявке в обслуживании достаточно разделить число заявок N , которым отказали за время Т (см. линейку «Отказанные»), па число заявок N, которые хотели обслужить за это же время, т. е. поступили в систему. Обратите внимание, что сумма Р оп + Р п(к в теории должна быть равна 1. На самом деле экспериментально получилось, что Р + Р. = 0,714 + 0,43 = 1.144. Эта неточность объясняется тем, что за время наблюдения Т накоплена недостаточная статистика для получения точного ответа. Погрешность этого показателя сейчас составляет 14 %.
- 4. Вероятность занятости одного канала Р = T r JT H = 0,05/5 = 0,01, где Т - время занятости только одного канала (первого или второго). Измерениям подлежат временные отрезки, на которых происходят определенные события. Например, на диаграмме ищутся такие отрезки, когда занят или первый, или второй канал. В данном примере есть один такой отрезок в конце диаграммы длиной 0,05 ч.
- 5. Вероятность занятости двух каналов Р = Т /Т = 4,95/5 = 0,99. На диаграмме ищутся такие отрезки, во время которых одновременно заняты и первый, и второй канал. В данном примере таких отрезков четыре, их сумма равна 4,95 ч.
- 6. Среднее количество занятых каналов: /V к - 0Р 0 + Р Х + 2 Р, = = 0,01 +2 ? 0,99= 1,99. Чтобы подсчитать, сколько каналов занято в системе в среднем, достаточно знать долю (вероятность занятости одного канала) и умножить на вес этой доли (один канал), знать долю (вероятность занятости двух каналов) и умножить на вес этой доли (два канала) и т. д. Полученная цифра 1,99 говорит о том, что из двух возможных каналов в среднем загружено 1,99 канала. Это высокий показатель загрузки, 99,5 %, система хорошо использует ресурсы.
- 7. Вероятность простоя хотя бы одного канала Р*, = Г прост,/Г = = 0,05/5 = 0,01.
- 8. Вероятность простоя двух каналов одновременно: Р = = Т JT = 0.
- 9. Вероятность простоя всей системы Р* =Т /Т = 0.
- 10. Среднее количество заявок в очереди /V з = 0P (h + 1 Р и + 2Р ъ = = 0,34 + 2 0,64 = 1,62 авт. Чтобы определить среднее количество заявок в очереди, надо определить отдельно вероятность того, что в очереди будет одна заявка Р, вероятность того, в очереди будут стоять две заявки Р 2з, и т. д., и снова с соответствующими весами их сложить.
- 11. Вероятность того, что в очереди будет одна заявка, Р и = = TJT n = 1,7/5 = 0,34 (всего на диаграмме четыре таких отрезка, в сумме дающих 1,7 ч).
- 12. Вероятность того, в очереди будут стоять одновременно две заявки, Р ъ = Г 2з /Г = 3,2/5 = 0,64 (всего на диаграмме три таких отрезка, в сумме дающих 3,25 ч).
- 13. Среднее время ожидания заявки в очереди Г рож = 1,7/4 = = 0,425 ч. Нужно сложить все временные интервалы, в течение которых какая-либо заявка находилась в очереди, и разделить на количество заявок. На временной диаграмме таких заявок 4.
- 14. Среднее время обслуживания заявки 7’ сробсл = 8/5 = 1,6 ч. Сложить все временные интервалы, в течение которых какая-либо заявка находилась на обслуживании в каком-либо канале, и разделить на количество заявок.
- 15. Среднее время нахождения заявки в системе: Т = Т +
г г ср. спет ср. ож
Если точность не является удовлетворительной, то следует увеличить время эксперимента и тем самым улучшить статистику. Можно сделать и по-другому, если несколько раз запустить эксперимент 154
на время Т и впоследствии усреднить значения этих экспериментов, а после этого снова проверить результаты на критерий точности. Эту процедуру следует повторять до тех пор, пока нс будет достигнута требуемая точность.
Анализ результатов моделирования
Таблица 3.11
|
Показатель |
Значение показателя |
Интересы владельца СМО |
Интересы клиента |
|
Вероятность обслуживания |
Вероятность обслуживания мала, много клиентов уходит из системы без обслуживания Рекомендация: увеличить вероятность обслуживания |
Вероятность обслуживания мала, каждый третий клиент хочет, но не может обслужиться Рекомендация: увеличить вероятность обслуживания |
|
|
Среднее количество заявок в очереди |
Практически всегда перед обслуживанием автомобиль стоит в очереди Рекомендация: увеличить число мест в очереди, увеличить пропускную способность |
||
|
Увеличить пропускную способность Увеличить количество мест в очереди, чтобы не терять потенциальных клиентов |
Клиенты заинтересованы в значительном увеличении пропускной способности для уменьшения времени ожидания и уменьшения отказов |
Для принятия решения о выполнении конкретных мероприятий необходимо провести анализ чувствительности модели. Цель анализа чувствительности модели заключается в определении возможных отклонений выходных характеристик вследствие изменений входных параметров.
Методы оценки чувствительности имитационной модели аналогичны методам определения чувствительности любой системы. Если выходная характеристика модели Р зависит от параметров, связанных с варьируемыми величинами Р =/(р г р 2 , р), то изменения этих
параметров Др.{/ = 1, ..г) вызывают изменение АР.

В этом случае анализ чувствительности модели сводится к исследованию функции чувствительности дР/ др.
В качестве примера анализа чувствительности имитационной модели рассмотрим влияние изменения варьируемых параметров надежности транспортного средства на эффективность эксплуатации. В качестве целевой функции используем показатель приведенных затрат З ир. Для анализа чувствительности используем данные по эксплуатации автопоезда КамАЗ-5410 в городских условиях. Пределы изменения параметров р. для определения чувствительности модели достаточно определить экспертным путем (табл. 3.12).
Для проведения расчетов по модели выбрана базовая точка, в которой варьируемые параметры имеют значения, соответствующие нормативам. Параметр продолжительности простоя при выполнении технического обслуживания и ремонта в днях заменен на удельный показатель - простой в днях на тысячу километров Н.
Результаты расчета приведены на рис. 3.24. Базовая точка находится в месте пересечения всех кривых. Приведенные на рис. 3.24 зависимости позволяют установить степень влияния каждого из рассматриваемых параметров на величину изменения З пр. В то же время использование натуральных значений анализируемых величин не позволяет установить сравнительную степень влияния каждого параметра на 3 , гак как эти параметры имеют разные единицы измерения. Для преодоления этого выберем форму интерпретации результатов расчетов в относительных единицах. Для этого базовую точку необходимо перенести в начало координат, а значения изменяемых параметров и относительного изменения выходных характеристик модели выразить в процентах. Результаты проведенных преобразований представлены на рис. 3.25.
Таблица 3.12
Значения варьируемых параметров

Рис. 3.24.

Рис. 3.25. Влияние относительного изменения варьируемых параметров на степень изменения З пр
Изменение варьируемых параметров относительно базового значения представлено на одной оси. Как видно из рис. 3.25, увеличение значения каждого параметра вблизи базовой точки на 50 % ведет к увеличению З пр на 9 % от роста Ц а, более чем на 1,5 % от С р, менее чем на 0,5 % от Н и к уменьшению 3 почти на 4 % от увеличения L . Умень- шение на 25 % Ь кр и Д рг ведет к увеличению З пр соответственно более чем на 6 %. Уменьшение на такую же величину параметров Н т0 , С тр и Ц а ведет к уменьшению З пр соответственно на 0,2, 0,8 и 4,5 %.
Приведенные зависимости дают представление о влиянии отдельно взятого параметра и могут быть использованы при планировании работы транспортной системы. По интенсивности влияния на З пр рассмотренные параметры можно расставить в следующем порядке: Д, II,L ,С 9 Н .
’а 7 к.р 7 т.р 7 т.о
В процессе эксплуатации изменение значения одного показателя влечет за собой изменение значений других показателей, причем относительное изменение каждого из варьируемых параметров на одну и ту же величину в общем случае имеет под собой неравнозначную физическую основу. Необходимо относительное изменение значений варьируемых параметров в процентах по оси абсцисс заменить параметром, который может служить единой мерой для оценки степени изменения каждого параметра. Можно предположить, что в каждый момент времени эксплуатации транспортного средства значение каждого параметра имеет одинаковый экономический вес по отношению к значениям других варьируемых параметров, т. е. с экономической точки зрения надежность транспортного средства в каждый момент времени оказывает равновесное влияние на все связанные с ней параметры. Тогда требуемым экономическим эквивалентом будет являться время или, что более удобно, год эксплуатации.
На рис. 3.26 представлены зависимости, построенные в соответствии с вышеприведенными требованиями. За базовое значение З пр принято значение на первом году эксплуатации транспортного средства. Величины варьируемых параметров для каждого года эксплуатации определялись по результатам наблюдений .

Рис. 3.26.
В процессе эксплуатации увеличение З пр в течение первых трех лет в первую очередь обусловлено ростом значений H jo , а затем, в рассмотренных условиях эксплуатации, основную роль в снижении эффективности использования ТС играет увеличение значений С тр. Для выявления влияния величины L Kp , в расчетах его значение приравнивалось к общему пробегу ТС с начала эксплуатации. Вид функции 3 =f(L ) показывает, что интенсивность снижения 3 с увеличением
пр J v к.р" 7 np J
1 к р существенно уменьшается.
В результате анализа чувствительности модели можно понять, на какие факторы необходимо воздействовать для изменения целевой функции. Для изменения факторов требуется приложить управляющие усилия, что связано с соответствующими затратами. Сумма затрат не может быть бесконечна, как и любые ресурсы, эти затраты в реальности ограничены. Следовательно, необходимо понять, в каком объеме выделение средств будет эффективно. Если в большинстве случаев затраты с увеличением управляющего воздействия растут линейно, то эффективность системы быстро растет только до какого-то предела, когда даже существенные затраты уже не дают такой же отдачи. Например, невозможно безгранично увеличивать мощность обслуживающих устройств из-за ограничений но площади или по потенциальному количеству обслуживаемых автомобилей и т. д.
Если сопоставить увеличение затрат и показатель эффективности системы в одних единицах, то, как правило, графически это будет выглядеть так, как представлено на рис. 3.27.

Рис. 3.27.
Из рис. 3.27 видно, что при назначении цены С, за единицу затрат Z и цены С, за единицу показателя Р эти кривые можно сложить. Кривые складывают, если их требуется одновременно минимизировать или максимизировать. Если одна кривая подлежит максимизации, а другая - минимизации, то следует найти их разность, например, по точкам. Тогда результирующая кривая (рис. 3.28), учитывающая и эффект от управления, и затраты на это, будет иметь экстремум. Значение параметра /?, доставляющего экстремум функции, и есть решение задачи синтеза.

Рис. 3.28.
чтобы по.
Кроме управления R и показателя Р в системах действует возмущение. Возмущение D= {d v d r ...} - это входное воздействие, которое в отличие от управляющего параметра не зависит от воли владельца системы (рис. 3.29). Например, низкие температуры на улице, конкуренция, к сожалению, снижают поток клиентов; поломки оборудования снижают производительность системы. Управлять этими величинами непосредственно владелец системы не может. Обычно возмущение действует «назло» владельцу, снижая эффект Р от управляющих усилий R. Это происходит потому, что, в общем случае, система создается для достижения целей, недостижимых самих по себе в природе. Человек, организуя систему, всегда надеется посредством ее достичь некоторой цели Р. На это он затрачивает усилия R. В этом контексте можно сказать, что система - это организация доступных человеку, изученных им природных компонентов для достижения некоторой новой цели, недостижимой ранее другими способами.

Рис. 3.29.
Если мы снимем зависимость показателя Р от управления R еще раз, но в условиях появившегося возмущения Д то, возможно, характер кривой изменится. Скорее всего, показатель будет при одинаковых значениях управлений находиться ниже, так как возмущение носит отрицательный характер, снижая показатели системы. Система, предоставленная сама себе, без усилий управляющего характера, перестает обеспечивать цель, для достижения которой она была создана. Если, как и ранее, построить зависимость затрат, соотнести ее с зависимостью показателя от параметра управления, то найденная точка экстремума сместится (рис. 3.30) по сравнению со случаем «возмущение = 0» (см. рис. 3.28). Если снова увеличить возмущение, то кривые изменятся и, как следствие, снова изменится положение точки экстремума.
График на рис. 3.30 связывает показатель Р, управление (ресурс) R и возмущение D в сложных системах, указывая, как наилучшим образом действовать руководителю (организации), принимающему решение в системе. Если управляющее воздействие будет меньше оптимального, то суммарный эффект снизится, возникнет ситуация недополученной прибыли. Если управляющее воздействие будет больше оптимального, то эффект также снизится, так как заплатить за очеред- 162
ное увеличение управляющих усилий надо будет по величине большей, чем та, которую вы получите в результате использования системы.

Рис. 3.30.
Имитационную модель системы для реального использования необходимо реализовать на компьютере. Это можно создать с помощью следующих средств:
- универсальной пользовательской программы типа математического (MATLAB) или табличного процессора (Excel) или СУБД (Access, FoxPro), которая позволяет создать только относительно простую модель и требует хотя бы начальных навыков программирования;
- универсального языка программирования (C++, Java, Basic и т. д.), который позволяет создать модель любой сложности; но это очень трудоемкий процесс, требующий написания большого объема программного кода и длительной отладки;
- специализированного языка имитационного моделирования , который имеет готовые шаблоны и визуальные средства программирования, предназначенные для быстрого создания основы модели. Один из наиболее известных - UML (Unified Modeling Language);
- программ имитационного моделирования, которые являются наиболее популярным средством создания имитационных моделей. Они позволяют создавать модель визуально, лишь в наиболее сложных случаях прибегая к написанию вручную программного кода для процедур и функций.
Программы имитационного моделирования делятся на два типа:
- Универсальные пакеты имитационного моделирования предназначены для создания различных моделей и содержат набор функций, с помощью которых можно смоделировать типичные процессы в системах самого разного назначения. Популярными пакетами этого типа являются Arena (разработчик Rockwell Automation 1 ", США), Extendsim (разработчик Imagine That Ink. , США), AnyLogic (разработчик XJ Technologies , Россия) и многие другие. Практически все универсальные пакеты имеют специализированные версии для моделирования конкретных классов объектов.
- Предметно-ориентированные пакеты имитационного моделирования служат для моделирования конкретных типов объектов и имеют для этого специализированный инструментарий в виде шаблонов, мастеров для визуального проектирования модели из готовых модулей и т. д.
- Конечно, два случайных числа не могут однозначно зависеть друг от друга, рис. 3.17, априведен для ясности понятия корреляции. 144
- Технико-экономический анализ в исследовании надежности автомобилей КамАЗ-5410 /Ю. Г. Котиков, И. М. Блянкинштейн, А. Э. Горев, А. Н. Борисенко; ЛИСИ. Л.:, 1983. 12 с.-Деп. в ЦБНТИ Минавтотранса РСФСР, № 135ат-Д83.
- http://www.rockwellautomation.com.
- http://www.cxtcndsiin.com.
- http://www.xjtek.com.
Как было сказано ранее, примерами распределений вероятностей непрерывной случайной величины Х являются:
- равномерное распределение вероятностей непрерывной случайной величины;
- показательное распределение вероятностей непрерывной случайной величины;
- нормальное распределение вероятностей непрерывной случайной величины.
Дадим понятие равномерного и показательного законов распределения, формулы вероятности и числовые характеристики рассматриваемых функций.
| Показатель | Раномерный закон распределения | Показательный закон распределения |
|---|---|---|
| Определение | Равномерным называется распределение вероятностей непрерывной случайной величины X, плотность которого сохраняет постоянное значение на отрезке и имеет вид | Показательным (экспоненциальным) называется распределение вероятностей непрерывной случайной величины X, которое описывается плотностью, имеющей вид |
 где λ – постоянная положительная величина |
||
| Функция распределения |  |
|
| Вероятность попадания в интервал |  |
|
| Математическое ожидание | ||
| Дисперсия |  |
|
| Среднее квадратическое отклонение |  |
Примеры решения задач по теме «Равномерный и показательный законы распределения»
Задача 1.
Автобусы идут строго по расписанию. Интервал движения 7 мин. Найти: а) вероятность того, что пассажир, подошедший к остановке, будет ожидать очередной автобус менее двух минут; б) вероятность того, что пассажир, подошедший к остановке, будет ожидать очередной автобус не менее трех минут; в) математическое ожидание и среднее квадратическое отклонение случайной величины X – времени ожидания пассажира.
Решение. 1. По условию задачи непрерывная случайная величина X={время ожидания пассажира} равномерно распределена между приходами двух автобусов. Длина интервала распределения случайной величины Х равна b-a=7, где a=0, b=7.
2. Время ожидания будет менее двух минут, если случайная величина X попадает в интервал (5;7).
Вероятность попадания в заданный интервал найдем по формуле:
Р(х 1 <Х<х 2)=(х 2 -х 1)/(b-a)
.
Р(5 < Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. Время ожидания будет не менее трех минут (т.е. от трех до семи мин.), если случайная величина Х попадает в
интервал (0;4). Вероятность попадания в заданный интервал найдем по формуле:
Р(х 1 <Х<х 2)=(х 2 -х 1)/(b-a)
.
Р(0 < Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Математическое ожидание непрерывной, равномерно распределенной случайной величины X – времени ожидания пассажира, найдем по формуле: М(Х)=(a+b)/2 . М(Х) = (0+7)/2 = 7/2 = 3,5.
5. Среднее квадратическое отклонение непрерывной, равномерно распределенной случайной величины X – времени ожидания пассажира, найдем по формуле: σ(X)=√D=(b-a)/2√3 . σ(X)=(7-0)/2√3=7/2√3≈2,02.
Задача 2.
Показательное распределение задано при x ≥ 0 плотностью f(x) = 5e – 5x. Требуется: а) записать выражение для функции распределения; б) найти вероятность того, что в результате испытания X попадает в интервал (1;4); в) найти вероятность того, что в результате испытания X ≥ 2 ; г) вычислить M(X), D(X), σ(X).
Решение. 1. Поскольку по условию задано показательное распределение , то из формулы плотности распределения вероятностей случайной величины X получаем λ = 5. Тогда функция распределения будет иметь вид:
2. Вероятность того, что в результате испытания X попадает в интервал (1;4) будем находить
по формуле:
P(a < X < b) = e −λa − e −λb
.
P(1 < X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Вероятность того, что в результате испытания X ≥ 2 будем находить по формуле:
P(a < X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Находим для показательного распределения:
- математическое ожидание по формуле M(X) =1/λ = 1/5 = 0,2;
- дисперсию по формуле D(X) = 1/ λ 2 = 1/25 = 0,04;
- среднее квадратическое отклонение по формуле σ(Х) = 1/λ = 1/5 = 1,2.
Функция распределения в этом случае согласно (5.7), примет вид:
где: m – математическое ожидание, s– среднеквадратическое отклонение.
Нормальное распределение называют еще гауссовским по имени немецкого математика Гаусса . Тот факт, что случайная величина имеет нормальное распределение с параметрами: m,, обозначают так: N (m,s), где: m =a =M ;
Достаточно часто в формулах математическое ожидание обозначают через а . Если случайная величина распределена по закону N(0,1), то она называется нормированной или стандартизированной нормальной величиной. Функция распределения для нее имеет вид:
|
|
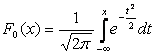 .
.График плотности нормального распределения, который называют нормальной кривой или кривой Гаусса, изображен на рис.5.4.

Рис. 5.4. Плотность нормального распределения
Определение числовых характеристик случайной величины по её плотности рассматривается на примере.
Пример 6 .
Непрерывная случайная величина задана плотностью распределения:![]() .
.
Определить вид распределения, найти математическое ожидание M(X) и дисперсию D(X).
Сравнивая заданную плотность распределения с (5.16) можно сделать вывод, что задан нормальный закон распределения с m =4. Следовательно, математическое ожидание M(X)=4, дисперсия D(X)=9.
Среднее квадратическое отклонение s=3.
Функция Лапласа, имеющая вид:
|
|
 ,
,связана с функцией нормального распределения (5.17), cоотношением:
F 0 (x) = Ф(х) + 0,5.
Функции Лапласа нечётная.
Ф(-x )=-Ф(x ).
Значения функции Лапласа Ф(х) табулированы и берутся из таблицы по значению х (см. Приложение 1).
Нормальное распределение непрерывной случайной величины играет важную роль в теории вероятностей и при описании реальности, имеет очень широкое распространение в случайных явлениях природы. На практике очень часто встречаются случайные величины, образующиеся именно в результате суммирования многих случайных слагаемых. В частности, анализ ошибок измерения показывает, что они являются суммой разного рода ошибок. Практика показывает, что распределение вероятностей ошибок измерения близко к нормальному закону.
С помощью функции Лапласа можно решать задачи вычисления вероятности попадания в заданный интервал и заданного отклонения нормальной случайной величины.


